
Demonstrating PCIe Performance
I’ve written about PCIe, and in particular the Cirrascale SR3514 part, in a few of my past blog posts – it’s what enables Cirrascale to create solutions that have large numbers of GPUs (or other devices) accessing each other directly. Davide Rossetti recently wrote a blog post describing the performance benefits of having GPUs and Infiniband cards communicate directly, as opposed to requiring intervention by the host CPU. The focus of Davide’s blog post was enabling GPUs in different systems to communicate directly (using GPU Direct – RDMA), but before introducing the complexity (and cost) of Infiniband, many workloads benefit from having a large number of GPUs in a single system.
The Cirrascale GB5470 makes use of two of the Cirrascale SR3514 parts to get 8 GPUs residing on the same PCIe Root Complex, as I’ve also written about previously.
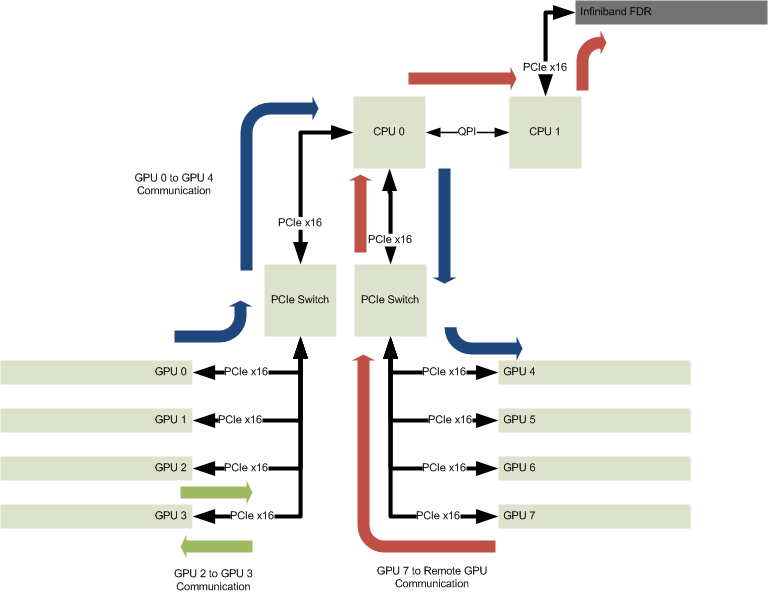
One of the questions that we get asked frequently about this particular PCIe topology is how data flowing between one set of cards impacts date flowing between different sets of cards. Looking at the picture above, two common questions are “What happens if GPUs 0 and 4 are communicating at the same time as GPUs 1 and 5?” and “If GPUs 0 and 4 are communicating, does that performance change when GPUs 2 and 3 start communicating?” Both are great questions, and have easy answers, but I like to be data informed (which is what I hear is the hip new term for “prove it”) rather than relying on theory. To answer these two questions, let’s take advantage of the fact that NVIDIA CUDA makes it trivial to copy data between GPUs and measure how long (in wall-clock) the copy took, and write a small program to measure the performance we’re interested in.
CUDA has a concept of “streams” (not unlike I/O streams in C++) where CUDA tasks are serialized. A task can be an action, such as moving bytes from one place to another, or what CUDA calls an “event”. An “event” is nothing more than a marker inserted into a stream. Since tasks are guaranteed by CUDA to complete sequentially, putting a pair of events on either side of an interesting task, such as a memory copy, lets us check see what period of time transpired between the two events, and therefore calculate the duration of the interesting task.

As I said before, this is trivial in CUDA. Assume we have two GPUs, “Device A” and “Device B”, and want to measure the time it takes to copy a known quantity of data between them, our trivial benchmark only has a few steps.
We first create our events, one for the start of the copy and another for the end of the copy:
cudaEventCreate(&AtoBstartEvent);
cudaEventCreate(&AtoBstopEvent);
Next, we create a stream for our events and memory copy to live in:
cudaStreamCreate(&AtoBstream);
After allocating a chunk of memory on Device A, and creating a place for it to live on Device B, we place objects into the stream in the order we want them executed. First, we place our “start” event in the stream:
cudaEventRecord(AtoBstartEvent, AtoBstream);
Then we do the memory transfer we’re interested in timing:
cudaMemcpyAsync(b_dest, a_source, bytes, cudaMemcpyDefault, AtoBstream);
And we then put in our “end” event into the stream, immediately after our transfer:
cudaEventRecord(AtoBstopEvent, AtoBstream);
We then wait until the “stop” event has worked it’s way through the stream, which we check for with:
cudaEventQuery(AtoBstopEvent) == cudaSuccess
With the “stop” event having occurred, we can then ask CUDA to measure the time between “start” and “stop”:
cudaEventElapsedTime(&time, AtoBstartEvent, AtoBstopEvent);
Since we know how much data we asked to be transfered (“bytes” worth, in the cudaMemcpyAsync() call above), and how long it took (“time”, populated by our cudaEventElapsedTime() call), we now know the transfer rate. Using less than a dozen CUDA function calls, we’ve created the framework for our trivial benchmark. Yes, I left out a lot of other stuff, like allocating memory, error checking, and handling the case where our “stop” event didn’t occur yet…but that’s generic code that doesn’t have much of anything to do with what we’re really trying to do. Taking this concept of Event-Task-Event to measure performance, it’s easy to think about other things that might be interested to do. Measuring Host-to-GPU performance rather than GPU-to-GPU performance is achieved by having “Device B” be Host memory, rather than a 2nd GPU. Having traffic flow in both directions between GPUs is simply doing two cudaMemcpyAsync() calls, one from Device A to Device B, and the other in the opposite direction.
Using a trivial benchmark tool using the concepts just discussed, we can now answer the questions posed earlier in this post. If you’d like to play along at home on your own Cirrascale GB5470, you can get the source here.
“What happens if GPUs 0 and 4 are communicating at the same time as GPUs 1 and 5?”
Running our benchmark on the GPU 0 and 4 pair, we measure 9.9 GB/s for the GPU 0 to GPU 4 transfer, and 9.3 GB/s for data in the opposite direction, for a total goodput of 19.2GB/s. Starting a second copy of the benchmark on the GPU 1 and 5 pair shows that communication occurring at 4.9GB/s in the GPU 1 to 5 and 0 to 4 direction and 4.7GB/s in the GPU 5 to 1 and 4 to 0 direction; for a total of 19.2GB/s.
|
Bandwidth (GB/s) |
|||||
|
GPU 0 -> 4 |
GPU 4 -> 0 |
GPU 1 -> 5 |
GPU 5 -> 1 |
Total |
|
| GPU 0/4 Only | 9.9 | 9.3 | N/A | N/A | 19.2 |
| GPU 0/4 & 1/5 | 4.9 | 4.7 | 4.9 | 4.7 | 19.2 |
Our answer is therefore “Bandwidth across the common PCIe x16 upstream ports is evenly shared.” The Avago (formerly PLX) PEX 8780 PCIe switch that is used in the Cirrascale SR3514 has a few different ways in which competing traffic can be handled. In the default configuration of the Cirrascale SR3514, the PCIe switch is configured to allow an equal number of packets to go upstream (toward the PCIe Root Complex) from each downstream device (GPUs in this case). Since the traffic between GPU pairs in our test is essentially identical (at least at the application layer…all things being equal it’ll be more-or-less the same traffic at the TLP layer as well), the resultant bandwidth ends up being the same between GPU pairs – half of the total available bandwidth.
“If GPUs 0 and 4 are communicating, does that performance change when GPUs 2 and 3 start communicating?”
The same methodology used above can be used to answer this question as well. Again, we start by running our benchmark on the GPU 0 and 4 pair, and obviously receive the same results as before: 9.9 GB/s for the GPU 0 to GPU 4 transfer, and 9.3 GB/s for data in the opposite direction, for a total goodput of 19.2GB/s. Running a second copy of the benchmark on the GPU 2 and 3 pair yields 10.5GB/s in the GPU 2 to 3 direction and the GPU 3 to 2 direction (that PEX 8780 is a pretty nice part!). Examining how that affected our GPU 0 and 4 traffic shows that it did not. GPU 0 and 4 continue to run at the original rate, providing 19.2GB/s of goodput.
|
Bandwidth (GB/s) |
|||||
|
GPU 0 -> 4 |
GPU 4 -> 0 |
GPU 2 -> 3 |
GPU 3 -> 2 |
Total |
|
| GPU 0/4 Only | 9.9 | 9.3 | N/A | N/A | 19.2 |
| GPU 0/4 & 1/5 | 9.9 | 9.3 | 10.5 | 10.5 | 40.5 |
Referring again to our PCIe topology picture, this is what should be expected. None of the PCIe communication paths overlap, so since no Cirrascale GB5470 port needs to be shared, every connected device is able to fully utilize the PCIe bandwidth.
For real-world applications where data needs to be shared between PCIe devices, the Cirrascale GB5470 with Cirrascale GB3514 cards can provide flexibility to communicate amongst devices with predictable bandwidth based on the needs of the consumers and producers. By taking advantage of a few CUDA functions, it’s easy to measure bandwidth and demonstrate that predictability.
cudaMemcpyAsync() in flight at all times, sandwiched between the necessary CUDA Events. If executed with a single argument, that argument is taken to be the GPU index (e.g., “ExercisePCIe 3″ will run on the 4th CUDA device installed in the system) which copies data to and from Host memory. If given two arguments, they are taken to be two GPU indexes, and data is copied between those two GPUs (e.g., “ExercisePCIe 0 1″ will copy data between the 1st and 2nd CUDA device installed in the system) without host intervention (since cudaDeviceEnablePeerAccess() is called unconditionally).








Recent Comments