
Welcome “Big Sur”
My inbox and RSS reader were replete with emails and articles today about Facebook’s “Big Sur” system. Most of the articles are the usual stuff – a rephrasing of Facebook’s announcement along with some verbiage around how “AI” (what Facebook calls Deep Learning) is actively transforming our lives. Basically, the “Big Sur” system is purpose built to facilitate Machine Learning by connecting 8 NVIDIA GPUs together using PCIe – a configuration which Facebook says “can train twice as fast and explore networks twice as large” as “the off-the-shelf solutions in our previous generation”.
This is great to hear from Facebook, because it’s what I’ve been hearing from our partners and customers for years now.
As I’ve talked about in prior blog posts, Cirrascale has been building systems with 8 GPUs and configurable PCIe topologies for a few years now. What I glean from the “Big Sur” announcement is that the system is x86 based, and can accommodate 8 GPUs (such as NVIDIA M40s) in a fully or partially peered configuration. The conclusion that this is ideal for Machine Learning is the same one that Cirrascale and our partners reached. Consider the Cirrascale GB5600 and GX8 products, which have the PCIe topology shown below.
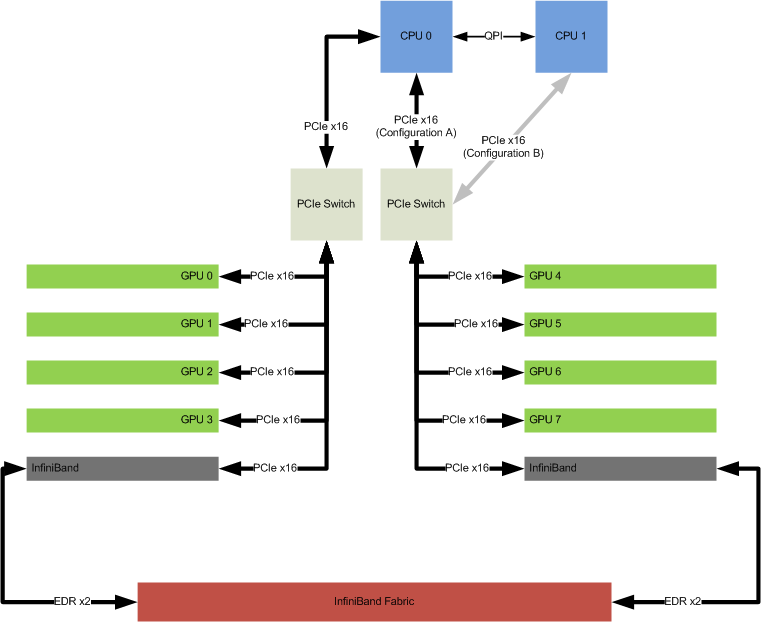
Like the “Big Sur” system, this enables 8 NVIDIA M40 GPUs to be peered together so that communication between GPUs can take full advantage of the PCIe Gen3 x16 bandwidth. It also enables direct GPU communication with Mellanox InfiniBand cards to get optimal performance between systems (I am assuming the “Big Sur” system includes some provision for I/O cards on the same PCIe Root Complex as the GPUs). The performance of this architecture isn’t just theoretically good; partners such as Samsung Research America are using Cirrascale systems and achieving impressive results like this:
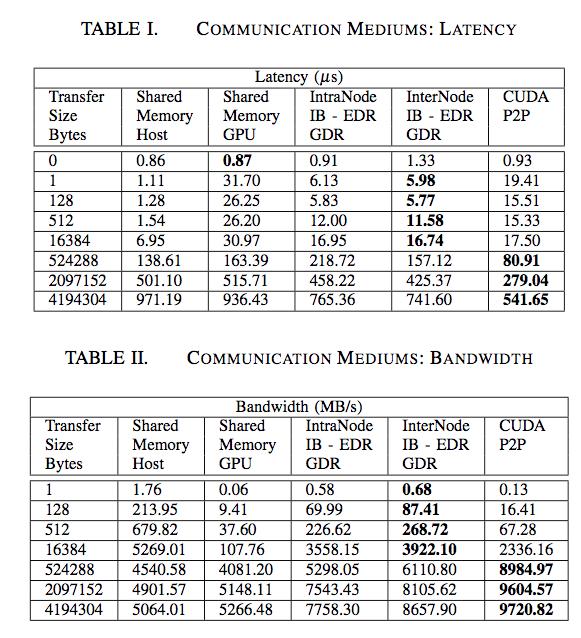
(These particular results are with NVIDIA K80 GPUs and single-port Mellanox Connect-X4 EDR InfiniBand cards connected to a Mellanox EDR switch, using Configuration B from the diagram above)
An architecture providing that type of performance turns out to be a great basis for Machine Learning, with common Deep Learning frameworks such as Caffe, Torch7, and Theano now starting to take advantage of these capabilities. Our GX8 system garnered a lot of attention at NIPS 2015 for that very reason.
I’m excited that Facebook has plans to make the “Big Sur” specifications available for those who have adopted OpenCompute. The way Cirrascale approaches systems is always about being open and having choice. The separation of PCIe interconnects from the host lets our customers choose an optimal host platform, be that changing the number of sockets, cores, or processor generation on the x86 host, or even changing to a completely different architecture (like Power8) all together. Designing to support high-power devices in a multitude of form-factors lets partners be free to use actively cooled cards like the NVIDIA Titan X, mixed-precision cards that excel at Deep Learning like the NVIDIA Tesla M40, or 300W cards with multiple GPUs to tackle demanding double-precision workloads like the NVIDIA Tesla K80. Having a BladeRack2 formfactor GB5600 for customers who want a unique, appliance-based solution, or the same capabilities in a traditional 19″ rackmount to fit in with existing equipment gives our customers choice.
I’m very excited to see the Machine Learning community get even more choices. Welcome to the Deep Learning family, “Big Sur”!








Yeah, we had a GX8 system in the NVIDIA booth at NIPS – glad you were able to see it, and thanks for the compliment on it!
The M40 cards are fast, but yeah…pretty pricey. You can always consider using Titan X (or GTX 980Ti cards, if you’re not memory-bound) for development and initial training, then moving to if you need the Tesla features (RDMA, ECC, etc.).
Another option is using http://www.GPUasaService.com/ to do development. We’ve tried to make that a lower capital expense for folks to get on high-performance machines.
Just ran across this post. I am a deep learning researcher and was at the NIPS conference this week. I think I saw your system in a booth while I was there (maybe nvidia or ?). It looked nice. My issue was that the cards are so expensive. I like M40 but I heard they are very pricey. The topology above looks impressive and the results are exciting. I need to find money for this.
(Oops, I’m a dummy and forgot to hit the “Reply” next to your message!)
Yeah, we had a GX8 system in the NVIDIA booth at NIPS – glad you were able to see it, and thanks for the compliment on it!
The M40 cards are fast, but yeah…pretty pricey. You can always consider using Titan X (or GTX 980Ti cards, if you’re not memory-bound) for development and initial training, then moving to if you need the Tesla features (RDMA, ECC, etc.).
Another option is using http://www.GPUasaService.com/ to do development. We’ve tried to make that a lower capital expense for folks to get on high-performance machines.